
Decision Transformer for Robotic Arm Manipulation
Traditional methods in reinforcement learning iteratively update a policy function to optimize over non-continuous reward spaces. Recent work has demonstrated the possibility of reformulating these reward-based sequential decision problems as sequence learning problems. Simultaneously, the recent dominance of transformer models for sequence learning tasks has spurred research efforts to evaluate what domains can benefit from the powerful long-distance relationship learning possible with this architecture. The Decision Transformer seeks to unify these two principles with a generative trajectory modeling approach and a framework for large, interdependent sequence inputs. We extend the use of decision transformers to robotics control and demonstrate feasibility for this architecture to learn to control a 7-DoF robotic manipulator used to manipulate a simulated object.




To formulate this reinforcement learning problem as a sequence understanding problem, we represent each step of the simulation as a state-action-reward tuple. Each input to our model then is a sequence of state-action-reward tuples, representing each timestep in the trajectory. We use the GoFAR dataset, which provides 40,000 action trajectories generated from a random control policy, and 4,000 trajectories generated from an expert policy. These policies control a 7-DoF robotic manipulator arm simulated in MuJoCo, from the Gymnasium-Robotics library of reinforcement learning environments.
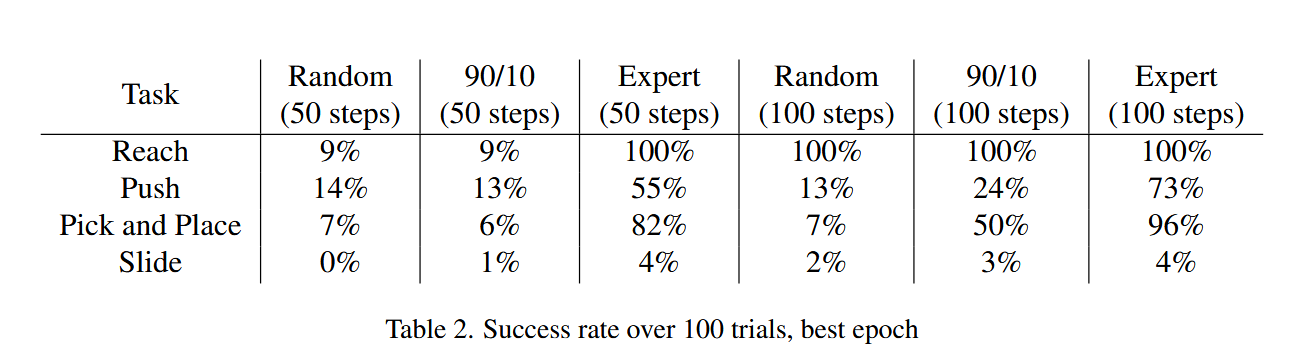
We find that our decision transformer model, trained only on randomly synthesized control trajectories, is able to successfully complete the Reach task in 100% of trials. Using a combination of expert and randomly synthesized trajectories enables our model to learn more complex controls tasks. We find that Decision Transformers are able to effectively clone expert policies in an offline RL environment.
You can find the source code for our model and experiments here, and a more in-depth writeup here